Parsely Part I
It's all nothing more than an idea for the time being, but I am working on a program.
The whole thing is about working better and more easily, and is the working result of many thoughts, more conversations and a lot of tinkering to get more familiar with how the hell you even build such a thing. A few weeks ago I barely knew how to write any kind of TypeScript, and now I've gotten to (kind of, a little bit) understand how a React frontend and python backend can communicate.
Back to the idea: Reducing the time between an idea and being in a state to share it with others.
From thought to execution.
Especially in investing there is often low time to decision, and a high volume of data potentially to be processed.
Such a system has to cut through that time by essentially multithreading data analysis with AI and context awareness.
There are many elements to this: The collation of relevant research (Articles, financial / computer models), alternative data, presentations and research reports.
This data has to be grouped (e.g. by time, geography, sector or business unit) but we also have to understand the context between elements.
It may be the case for example that we have a Q1 report which mentions the construction of a new power plant in Sweden for our fictional research target, and highlights that there is uncertainty on the execution of this development. We hear nothing further in the subsequent quarterly reports, but there is a press release 11 months later that mentions in some detail why the project fails, and that it happened as a result of financial mismanagement.
We digest both pieces of information and may find it sensible to include these in our investment thesis, but
- May not remember if we do not immediately write it down - even a simple highlight can be forgotten in mountains of pages
- May struggle for time to think through potential implications - for example how could a criminal investigation affect the bond and its covenants
Can we then build an agentic tool that is our research assistant more comprehensively than 'just' a note taking app, a product which learns about our interactions with data (notes, highlights, comments), and can order the association between tokens across time and documents?
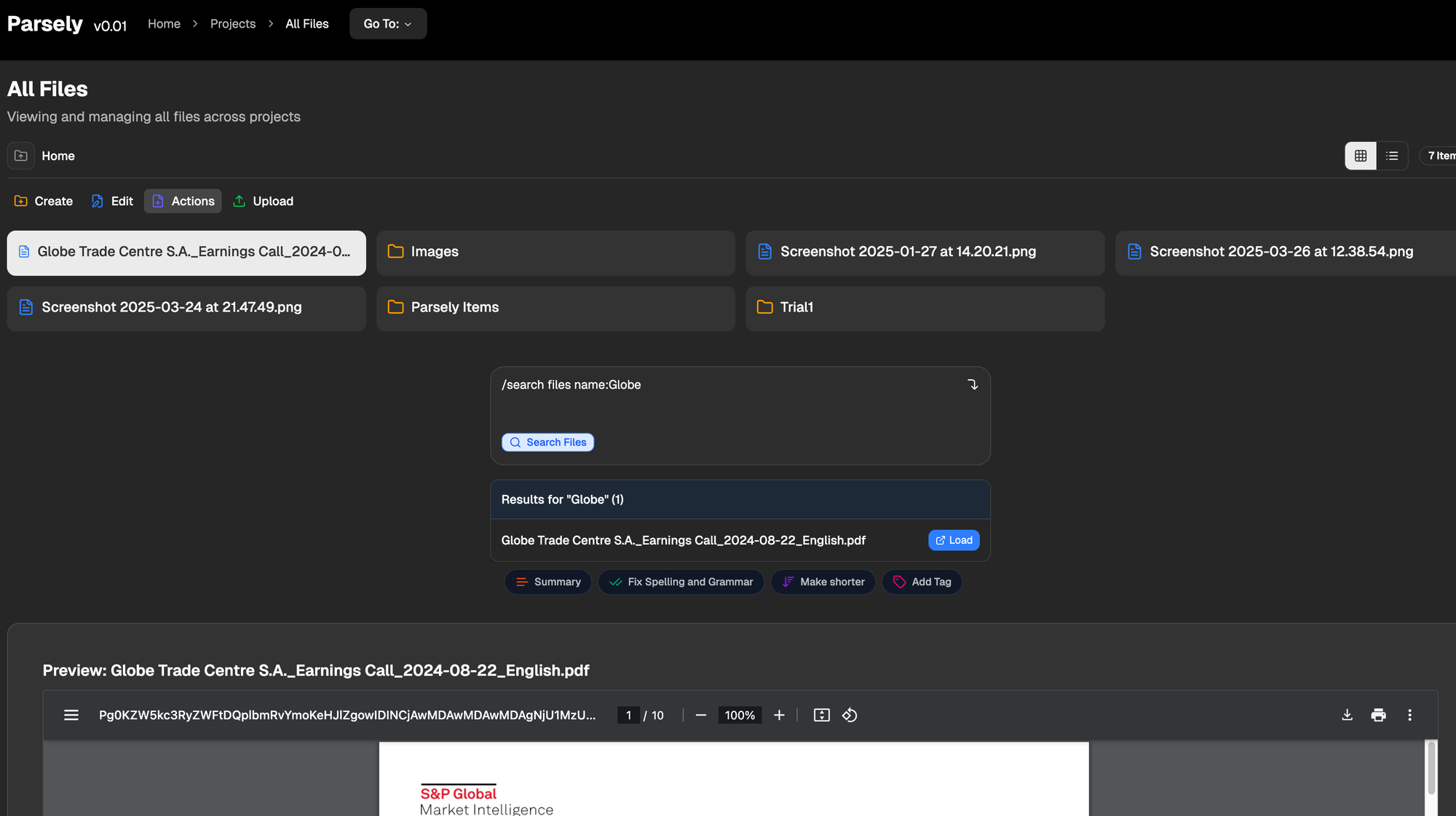
First, we build search - we need to understand how best to find what we are looking for when we know exactly what it is. Direct user input must lead to the correct output.
If I have one file called 'Globe Trade...', and no other files with Globe, then we have to at least return that file. Neat. Building this search took a long time. I have no idea how long it should take to write a search functionality, especially since it's not like I wrote it myself, we're actually just using convex and it handles search. Anyway it works, roughly.
There's a lot for the future, most excitingly (for me) integrating this into a writing workflow.
The to-do list is growing longer with each item that even gets considered, but it's all exciting to me, because the utility of the idea feels clear.